RAID is about up-time. Or about the chance to avoid having to restore from backup if you are lucky. RAID is not a backup, though. There are also no backups, just successful or failed restores. (Those are the most important proverbs that come to my mind right now.)
Given that I’m obsessed with backups, but also “lazy” in the sense that I want to avoid having to actually restore from my backups, I’ve been using RAID1 in my data store for at least 15 years now. For the first 12 years of them, I’ve been using ext3/4 on top of mdadm managed RAID1. About 3-4 years ago, I switched most of my storage to Btrfs, using the filesystem’s built-in RAID1 mode.
In this article I want to give a short reasoning for this. I initially wanted this article to kick-off a mini-series on blog-posts on Btrfs features that you might find usable, but due to some discussion on Mastodon, I already previously posted my article about speeding up Btrfs RAID 1 up using LVM cache. You should check that one out as well.
Btrfs still has the reputation of being experimental and to sometimes lose your data. From my personal experience, if you avoid doing things that are marked as “experimental” in the documentation, I cannot agree with this. For the past years, it has proven to be quite stable in my setup and the advantages of the filesystem outweigh the additional complexity for me personally. Btrfs is not a zero maintenance filesystem. While you can set it up once and then forget about it, the most benefits require some maintenance by the admin to really prove valuable. This will be part of a later blog-post in the Btrfs series.
Side-note: Btrfs vs. ZFS
ZFS enthusiasts (correctly) will point out, that all I write here is also available on ZFS and that ZFS is much more mature and that it is easier to administrate. I guess that’s true for many things. However, I wanted to use a “native” Linux filesystem, one that’s available from the kernel directly and does not rely on workarounds due to licensing. ZFS-on-Linux (and OpenZFS) is an awesome project, and one day I’ll try it. For now, the missing support for cp --reflink=always is something that’s holding me back, but that’s for another blog-post.
Why Btrfs RAID1 is superior to mdadm for some use-cases
Bit-Rot Detection
Btrfs is what’s called a copy-on-write filesystem. I don’t want to explain this too much here, the Btrfs wiki does a well-enough job on this. Basically blocks are not overwritten in place but copied elsewhere on change, by default. As part of this, a checksum for the data-block is calculated. This checksum is verified on read. Therefore the filesystem can detect errors, caused by “bit rot” of the hard-disk or other factors that lead to data corruption.
And this is a huge advantage over default mdadm raid1’s already. First of all, MD operates on the block device level. It has no knowledge about the meaning of the data it returns. While this separation of concern is good and well-established, it also brings the problem that MD cannot determine if there is anything wrong with the data it read. And it will return the data of one of the mirrors, more or less random. If there was bit-rot on the device, MD will not notice. There are maintenance tasks for MD (analyze, repair), that you can trigger so that both sides of the mirror are compared and differences are fixed, but this basically just overwrites data on the non-main devices with data from the main-device, if a difference is found.
For Btrfs on the other hand, if a checksum error is found, the filesystem will attempt to retrieve a valid copy from the other side of the mirror. So the checksum can be used to determine the valid copy of the data, and the valid copy can be used to repair the corrupted side of the mirror.
To be fair, there is dm-integrity, which allows DM mirrors to also include integrity information. I have not experimented with that so much, since for my use-cases Btrfs provides a lot of advantages beyond this aspect. I’d be very interested to get comments from users of dm-integrity, if this works well for them, though.
Bit-rot detection also works for single-disk use-cases, but of course without the possibility to repair from an unaffected copy. But at least you know when you have to restore from backup.
Different-sized Disks
For mdadm, a RAID1 can consist only of equally sized disks (or partitions). So if you have three disks with e.g. 1TB, 1TB, and 2TB, you can set up a 3-disk RAID1 with the capacity of 1TB maximum. This RAID1 will survive the failure of 2 devices, since there are three copies of the data distributed over 3 different disks.
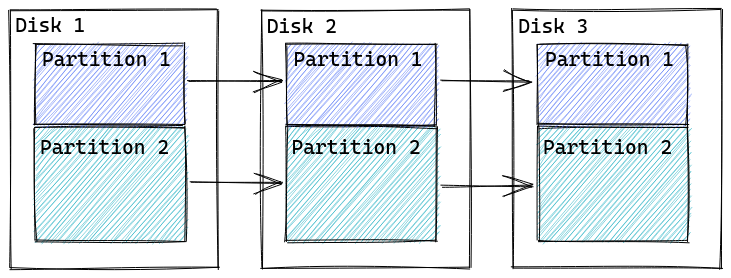
On Btrfs, RAID1 means that every data is available with one additional copy, on two different disks. And since it’s not a mirror on the block-device layer, it actually does not care about on-disk positions, just that the copies have to be on two different devices. As a consequence, Btrfs RAID1 can consist of many different devices with different capacity, as long as the capacity of the largest device is less or equal to the sum of all other devices. Therefore in the above example, the 3 disks would result in capacity of ~1.5TB of available disk space. The RAID1 however would only survive the loss of a single disk! (See Pitfalls section below.)
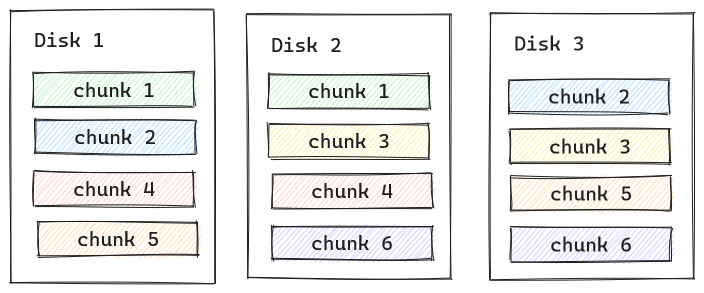
Btrfs RAID Pitfalls
Handling of degraded RAID
While RAID is about uptime, Btrfs raid has a corner case, where it actually reduces uptime: by default Btrfs refuses to mount degraded arrays, i.e. if a device failed, even only intermittent. And there are some very good reasons for it, because if you force degraded mounts, you may end up without redundancy, if you don’t handle the temporarily failed disk correctly (spoiler for future blog-post: you need a btrfs balance in this case).
An mdadm raid1 will mount in degraded state, ZFS will mount in degraded state, and both of them will start a “resync” (mdadm) or “resilvering” (ZFS) in case the missing device is suddenly available again (e.g. SATA cable was loose).
From a pure uptime perspective, automatic resync/resilvering or even running in degraded mode is what is wanted. You want the RAID to be available as much as possible. You for sure don’t want it to block a server coming back up after a reboot.
From a data-integrity point-of-view, it may arguably be better that a mount fails in such a scenario. While the “resync” or “resilvering” is running, you are actually running without redundancy. If the good disk fails before it is finished, you have a problem. So you might prefer to know that you are currently in a situation without redundancy. So I personally prefer to be hands-on in this situation, since for my personal use-case data-integrity > uptime.
Your mileage may vary, and in this case, a hardware RAID or ZFS’ approach may be better suited. And of course you could always run Btrfs on top of another (software) RAID if you just want the other cool filesystem features but not the RAID handling. But in this case recovery in case of bit-rot depends on the handling of the underlying RAID implementation (maybe dm-integrity will help).
Btrfs RAID1 == 2 Copies!
This is basically the other perspective on what I mentioned as an “advantage” above for more than two disks: while in madm having more disks increases redundancy, this is not the case for Btrfs RAID1! I repeat: Btrfs1 redundancy is not increased by adding additional drives! You always get two copies of the data, and it can tolerate the loss of a single drive. Lose more than a single drive, and you lost your array, and most likely all data on it.
If you want more than one copy, you can have 3 or 4 copies by using the RAID level raid1c3 and raid1c4. Since metadata is crucial to not be corrupted to be able to salvage anything off of Btrfs, I personally use raid1c3 for metadata and raid1c2 (the default “raid1”) for data.
RAID5/RAID6 are highly experimental! You may (will?) lose data!
The Btrfs wiki has a scaring warning about RAID5/RAID6. While it seems that with well-enough care (metadata in raid1c3 and only data in raid5/raid6) and knowing what to do in case of failed disks, it is possible to use Btrfs in this mode in the meantime, I personally only stick to RAID1 since I can tolerate the additional loss in capacity.